-
LEVER: Learning to Verify Language-to-Code Generation with Execution 논문 리뷰Paper Reviews 2023. 8. 16. 23:36
META AI
ICML 2023
Language-to-Code generation에서 풀어야 하는 문제들
SPIDER / WIKITQ / GSM8K / MBPP 공개 데이터셋들

SPIDER/WIKITQ 예제 
GSM8K 예제 
MBPP 예제 방법론
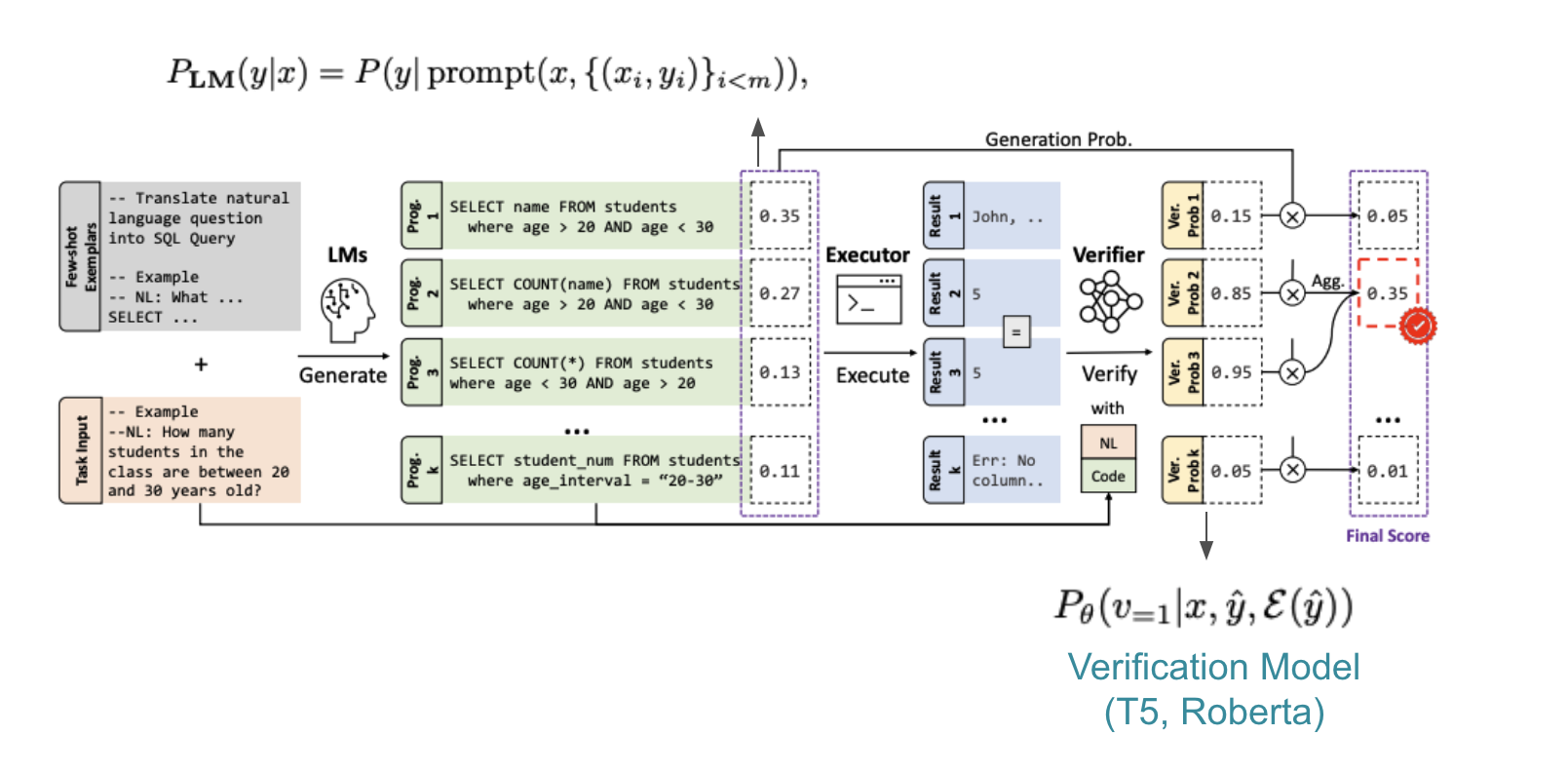


code 실행 결과가 같은 것끼리는 확률을 
실험 결과





짱먹고 있는 GPT4 few-shot 
Calibration of verifier, generator, and their combined probability. 처음 샘플들을 추리기 시작할 때는 verifier threshold로 가르는 것이 generator threshold로 가르는 것보다 성공률이 더 높다 (verifier is better calibrated than the generator)
하지만, 제일 가능성 있는 몇 개 프로그램에서 가를 때는 verfier 점수는 별 도움이 안된다. 차라리 generator threshold가 더 낫다.
verifier + generator 곱해서 같이 측정하면 잘 calibrated 된다.
LEVEL dfed
'Paper Reviews' 카테고리의 다른 글
상용화된 LLM에서 얻은 피드백 활용 방법 (0) 2023.10.31 LLAMA2를 무해한 모델로 만들기 위한 노력 (0) 2023.08.24 TaskMatrix.AI (0) 2023.08.16 captum으로 내가 만든 pyTorch 모델 결과 분석하기 (XAI) (0) 2023.03.21 네이버와 Meta AI의 Multimodal Shopping Model 비교 분석 (0) 2023.01.25