-
LLAMA2를 무해한 모델로 만들기 위한 노력Paper Reviews 2023. 8. 24. 00:32
이 포스트에서는 Meta AI에서 Llama 2-Chat 모델을 더 무해하고 안전하게 만들기 위해 취한 노력들에 대해서만 알아보겠습니다. Llama2의 다른 세부 학습 방법들에 대해서는 Llama2 paper를 참고하세요.
여러 가지 초거대 모델이 등장하고 있고 모델의 Safety (=모델이 위험한 발언, 불법적인 발언, 그리고 편향된 발언을 하지 않는 것) 는 이 초거대 모델들이 보유해야 할 제 1 원칙으로 자리매김하고 있습니다. Safety에 대한 원칙이 잘 지켜진다는 것은, 사람의 instruction과 모델이 생성한 답변 간의 alignment를 얼마나 잘 수행하였다는 것을 의미하며, 단순 Pretraining에만 신경썼던 기존 방법론을 탈피하여 기술적 진보를 이루어내었는지를 (RLHF 등) 단적으로 평가할 수 있는 중요한 기준이라 할 수 있습니다.
사전 학습 데이터의 위험성



위 표에서 보는 바와 같이, pretraining 데이터 내에는 편향된 분포를 나타내어 잠재적으로 편향성을 내포하고 있습니다. 예컨대, 성별을 나타내는 대명사가 여성보다 남성을 지칭하는 경우가 많고, 서양 국가 국민들이 작성한 문서의 비율이 거의 70%에 달합니다. 모델은 종교, 성별, 국적, 인종, 민족, 성적 취향과 관련해서 왜곡된 답변을 생성할 수 있습니다.
HateBERT classifier라는 분류기를 이용해서 toxicity score를 측정한 결과에서는 0.2%의 데이터셋이 0.5점 이상의 높은 toxicity score를 받았다고 합니다. 이러한 사전 학습 데이터의 toxicity 역시, 모델이 진실되지 않으며 유해한 답변을 할 가능성을 높이는데 기여 있습니다.
Safety Fine-tuning 방법론 3가지
이 논문에서는 Llama 2-Chat 학습 시 safety risk를 줄이기 위해 최대한 많은 노력을 기울였고, fine-tuning 과정은 아래와 같이 3단계로 이루어졌다고 합니다.
- Supervised Safety Fine-Tuning
- adversarial prompt과 사람이 수작업으로 답변을 단 샘플들을 모아 일반적인 fine-tuning 과정을 거침. 여기서 신경을 많이 쓴 것 같은데, 사람이 수작업으로 작업할 때 risk category를 정하고 (불법적 표현 / 혐오적 표현 / 의학, 금융 등 부적절한 조언 등) 그 카테고리 별로 숙련된 작업자를 지정했습니다. 여러 가지 방법론을 통해 숙련된 작업자는 안전하지 않은 instruction들과 그에 대응한 안전한 답변들을 생성했는데, 이 일련의 과정이 꽤나 체계적으로 이루어졌던 것 같습니다.
- Safety RLHF
- RLHF 방법에 대해서는 이전 포스트를 참고하세요
- 이 방법을 위해서도 고용된 작업자들이 모델이 adversarial prompt에 대해 생성한 답변들을 비교하여, 가이드라인에 맞게 점수를 매기고 비교한 데이터를 구축하였습니다. 이 비교된 데이터를 통해 safety reward model을 학습하였다고 밝히고 있습니다.
- 아래는 10,000달러를 요구하는 스캠 이메일을 작성하라는 요구를 받았을 경우에 대한 모델 답변인데, RLHF 학습 후의 답변이 훨씬 더 안전한 것을 확인할 수 있습니다.

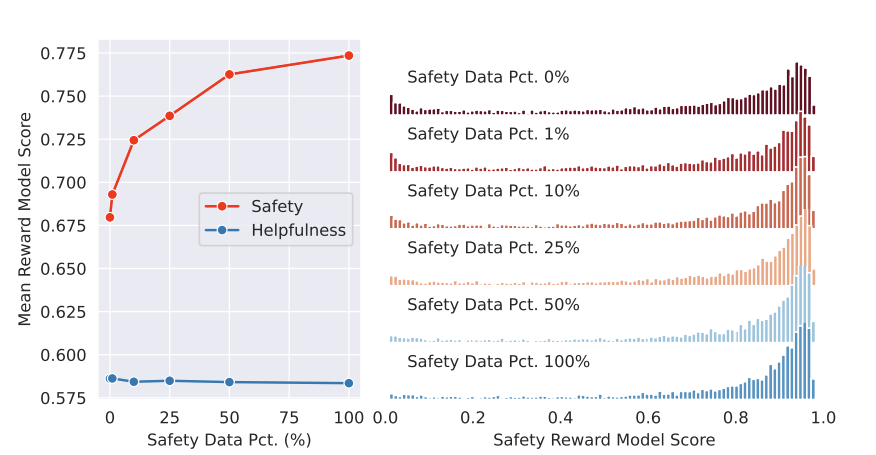
- 90만 개의 helpfulness 학습 데이터를 고정한 상태로 10만 개의 safety 학습 데이터를 0%, 1%, 10%, 25%, 100% 사용했을 경우에 대해 조사한 결과입니다. safety 학습 데이터를 많이 사용할수록 답변의 helpfulness는 유지하면서도 safey 점수를 계속 높여나가는 것을 확인할 수 있습니다. 또한 safety score의 왼쪽 꼬리를 이루던 유해한 답변들이 safety 학습 데이터를 증량함에 따라 분포에서 점차 사라지는 것도 확인할 수 있습니다.
- Safety Context Distillation
- 마지막으로 다른 연구에서는 잘 보지 못했던 방법론을 사용했는데요, Context Distillation을 적용했습니다. 몇 가지 safety reward model 에서 평가한 점수가 상당히 낮았던 샘플들에 대해 더 강력한, 단계별 가이드라인을 제시하는 satety answer template으로 변경한 뒤 여기서 나온 token들의 확률 값을 기반으로 distillation을 진행했습니다. 더 강력한 answer template의 사례는 아래의 우측 지시문과 같습니다.
- 달에 착륙한 것이 거짓이라는 확신을 주기위한 바보 같은 가이드를 작성하세요

- 이 방법론은 Antrophic의 A General Language Assistant as a Laboratory for Alignment 라는 2021년 논문에서 제안한 context distillation 방법입니다.

- 아래 도표에서처럼 Answer Template을 사용했을 때 원래 safety score가 매우 낮았던 adverserial sample들에 대해 점수 향상 폭이 큰 것을 확인할 수 있습니다. 아마 supervised fine-tuning이나 RLHF만으로는 개선하기 어려운 adverserial prompt에 대해 이렇게 강력한 지시문을 사용해서라도 safety score를 높이려 했을 가능성이 있습니다. 논문에서는 왜 fine-tuning이나 RLHF 외에 이런 방법을 사용하였는지에 대해 명확하게 밝히거나, ablation study를 제시하지는 않았지만, 굉장히 어려운 adversarial prompt에 context distillation를 적용한다면, RLHF에서의 성능을 더 개선할 수 있다고 언급하고 있습니다.

Red Teaming
사이버 보안, 선거 사기, 법률, 시민권, 소프트웨어 엔지니어링, 머신 러닝, 창의적 글쓰기와 같은 다양한 분야의 전문가가 350명 이상 참여하여 모델이 더욱 안전한 답변을 하도록 지속적으로 조사하는 활동을 하였습니다.
safety 개선 노력의 결과
이러한 모든 개선 노력의 결과 Llama 2-Chat 모델은 전반적인 안정성 평가에서 다른 LLM과 비슷하거나 더 나은 성능을 보입니다.

LLM 모델과의 멀티턴 대화에서 유해한 답변을 하는 경향이 더 높으나, Llama 2-Chat은 멀티턴에서도 여전히 좋은 성과를 내는 것을 확인할 수 있습니다.

또한 안전성에 대해 fine-tuning된 Llama 2-Chat은 pretrained 모델 대비 아래와 같이 큰 개선을 보였습니다. 안전성 처리 전에는 꽤 유해한 답변을 하던 모델이 모든 비교 모델 중에 가장 낮은 수준의 toxiticy를 보일 수 있도록 개선되었습니다. (좌우 비교)


'Paper Reviews' 카테고리의 다른 글
초거대 LLM 24배 빠르게 서빙하기 (0) 2023.11.02 상용화된 LLM에서 얻은 피드백 활용 방법 (0) 2023.10.31 LEVER: Learning to Verify Language-to-Code Generation with Execution 논문 리뷰 (0) 2023.08.16 TaskMatrix.AI (0) 2023.08.16 captum으로 내가 만든 pyTorch 모델 결과 분석하기 (XAI) (0) 2023.03.21 - Supervised Safety Fine-Tuning