-
[논문 리뷰] Direct Preference Optimization (DPO) Explained!Paper Reviews 2024. 1. 5. 15:40

Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Stanford University
이번에 소개드릴 paper는 Large Language Model (LLM)을 사람의 의도에 align하는 기법에 혁신적인 변화를 가져온 중요한 논문입니다.
최근 공개된 업스테이지 SOLAR-10.7B 모델 역시 PPO가 아닌 DPO 알고리즘을 활용하여 높은 성능을 내었답니다.
출처: 챗봇 딥러닝 - LLM의 새로운 기법 - Merge와 DPO (aidev.co.kr)
챗봇 딥러닝 - LLM의 새로운 기법 - Merge와 DPO
요즘 LLM에서 Merge와 DPO가 많이 쓰이고 있습니다. 얼마 전 공개된 업스테이지 SOLAR-10.7B도 이 두가지 기법을 사용했습니다. Merge는 두 개 이상의 모델을 섞어서 하나의 모델로 만드는 방법입
aidev.co.kr
이 글은 LLM과 기존 RLHF 방법론들에 대한 이해를 바탕으로 쓰여졌습니다.
RLHF와 PPO 알고리즘에 대한 자세한 설명은 본 블로그에 다른 글을 참고해주세요.
chatGPT에 사용된 RLHF와 PPO 알고리즘 뜯어보기
ChatGPT 아직 다들 잘 사용하고 계신가요? 과거 우리는 단순히 통계적으로 높은 확률의 토큰을 출력하는 기존의 생성 언어 모델(ex. GPT-2, GPT-3)의 한계를 명확히 보았습니다. 그럴싸하게 이야기를
dalpo0814.tistory.com

RLHF 기존 RLHF는 꽤 복잡한 학습과정을 거칩니다.
(1) 우선 사람의 선호도를 학습한 reward model을 먼저 학습시킨 뒤
(2) 강화학습(Reinforcement Learning , RL)을 활용하여 policy가 평가하는 reward를 최대화 하는 방식으로 학습
서비스에 성공한 많은 LLM들이 이런 PPO-based RLHF를 적용하여 무해하고, 안전한 답변을 생성을 하는 모델을 굽는 것에 성공했습니다. 그러나 RLHF의 과정을 자세히 들여다보면, 비용이 많이 들고 복잡하다는 것을 알 수 있습니다. RLHF를 위해서는 inference용 LLM인 policy model외에도, 사람의 선호도를 학습하는 reward model을 먼저 학습시켜야 하죠. 게다가 PPO 알고리즘을 사용한다면 value function으로 사용 되는 critic model도 policy model과 함께 학습되어야 합니다. 엄청난 계산 비용이 들거에요.
또 이렇게 정교한 알고리즘 하에서도 강화학습을 stable하게 진행하기가 힘들다는 단점이 있습니다. huggingface blog에서도 이렇게 instability를 일으키는 현상1, 현상2들을 보고한 것을 보면, 안정적으로 학습시키기 어려운 알고리즘이라는 것을 알 수 있습니다.
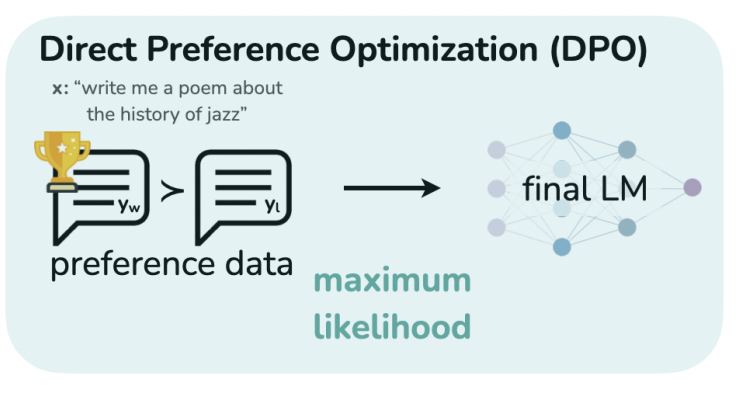
DPO DPO는 reward model 없이, 그리고 RL 없이 LLM policy model만을 학습하여, 사람의 선호도를 반영한 문장을 생성하도록 LLM을 직접적으로 최적화 하는 알고리즘입니다. 기존 RL을 활용한 alignment 방법보다 좋은 성능을 보여주면서도, 비교적 간단한 학습 파이프라인을 제시하여 사람 선호도와의 alignment를 위한 학습 방식의 혁신을 가져온 논문입니다.
Direct Preference Optimization (DPO)

loss function of DPO DPO의 loss 함수는 위와 같습니다. 수식을 파헤치기 전에 의미부터 살펴볼까요?
\( y_w \) , \( y_l \)는 prompt \( x \)를 reference model에 입력하여 샘플링한 2가지 결과입니다. \( y_l \) 는 사람이 평가한 결과 덜 선호되는 (lose) 샘플이고 \(y_w \)는 더 선호되는 (win) 샘플이라고 볼 수 있습니다. DPO 알고리즘은 이렇게 샘플링한 선호도 데이터의 쌍 여러 개를 이용하여 최적화 대상 모델 \( \pi_{\theta} \)에서 선호되는 샘플에 할당되는 확률 값은 높이고, 선호되지 않는 샘플의 확률 값은 낮추는 방향으로 학습시키려하고 있습니다.
이렇게 loss를 구성하는 방식은 reward model 학습이나 복잡한 RL 없이도 사람의 선호도를 직접적으로 학습할 수 있다는 장점이 있습니다.
이 수식은 사람의 선호도를 모델링하는 역사가 오래된 Bradley-Terry Model (1952) 로부터 시작합니다.
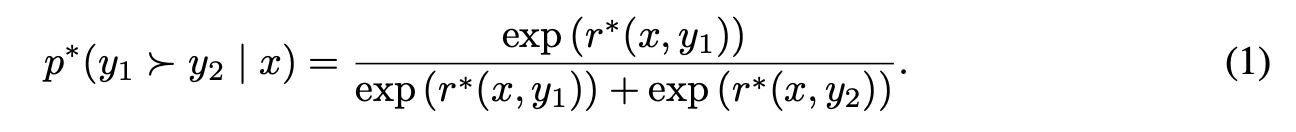
Bradley-Terry model에서는 reward model \( r^* \)를 사용하여 확률 분포를 구성하고 있습니다. 이런 상황에서 최적의 reward model은 이 확률 분포에 대한 maxium likelihood를 통해 학습될 수 있습니다. 익숙한 아래 유도 과정을 통해 negative log-likehood loss를 구성해보겠습니다.
더보기
(1) --> (2) 
negative log-likehood loss (2)번 수식이 RLHF에서 reward model을 학습하는 loss 입니다. 우리는 reward model parameters을 policy model parameters로 대체할 방법 (change of varible) 이 필요합니다. 저자들은 기존 RL 수식으로부터 그 방법을 찾아내었습니다.

(3) 수식은 (2)로부터 얻어낸 reward model을 활용하여 policy model을 학습시키는 reinforcement learning을 하려고 할 때 활용하는 loss function 이었습니다. 그런데 수학적으로, (3)을 만족시키는 optimal policys는 reward model을 활용한 수식으로 표현할 수 있다는 것이 알려져 있습니다.

(4) 수식에 간단한 변형을 통해 reward 함수를 좌변에 두고 policy를 우변으로 보내면, reward 함수를 policy 함수의 확률 분포로 표현할 수 있습니다. (3)의 constraint를 만족시키는 policy의 확률 값은 reference model의 확률 값에 reward의 지수함수 배를 곱해준 형태임을 확인할 수 있습니다. 또, constraint의 \( \beta \) 값을 키우는 것이, 최종 policy model의 확률 값에 어떠한 영향을 미치는지도 확인할 수 있네요.
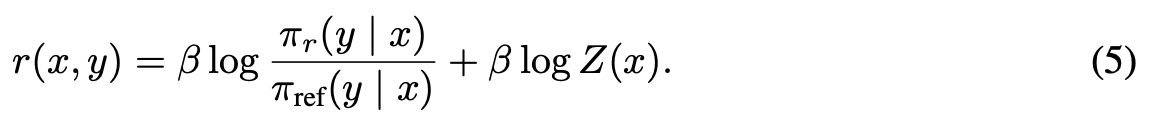
이제 이러한 형태의 reward 함수를 가정하고, (2)에서 정의된 loss에 대입하면 계산이 까다로운 partition function인 \( Z(x) \)에 대한 항이 사라지고, 위에서 봤던 형태 (7)로 정리가 됩니다!
loss function of DPO 이는 (2)의 Bradley-Terry Model을 최적화하는 과정에서 reward function의 형태를 (5)와 같이 제한함으로써, (2)의 최적화에 추가적인 RL constraint를 주는 것으로도 해석할 수 있습니다.
원래는 reward model을 먼저 학습한 후, RL training을 통해 optimal policy를 학습하는 2 step으로 구성되어야 하는 학습 과정인데요, reward model을 학습하는 과정에서부터 (5)의 change of varible을 통해 optimal policy를 바로 추정해버리겠다는 전략입니다. 이에 따라 학습 단계는 1 step으로 압축되고 RL training 과정도 사라지게 되는 것입니다.
개인적으로는 이러한 수식이 이론적으로 얼마나 정당성을 인정받을 수 있는가에 대한 의문이 있습니다만, 전체 flow 자체는 reasonable 한 것 같습니다...
마지막으로 이 loss (7)의 gradient를 구하여. DPO loss가 어떤 방향으로 모델을 최적화(학습)시키는지 알아보겠습니다.
더보기
위와 같은 sigmoid function의 특성을 활용하면, \(f(\theta) \)라는 함수를 아래와 같이 정의했을 때

(7) expectation 안의 함수의 gradient를 아래와 같이 표현할 수 있다 (by chain rule)
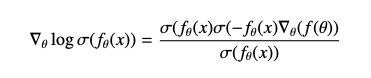
분자는 분모의 같은 항과 cancel되고, 나머지 항을 정리하면 아래와 같다.

이런 유도 과정을 통해 아래 gradient를 계산할 수 있다

gradient of DPO loss function 학습 방향이 수식적으로 \( \theta_{t} \) = \( \theta_{t-1} + (- \nabla_{\theta}L(\theta)) \) 이므로 parameter를 변화시키는 방향이 \( -\nabla_{\theta}L(\theta) \) 라는 것을 알 수 있습니다. 따라서 위 함수에서 expectation 안에 있는 수식은 학습 시 parameter가 움직이는 방향이 될 것입니다.
\( y_w \)의 log likelihood를 높이고 \( y_w \) 의 log likelihood는 낮추는 방향이라는 것은 쉽게 파악가능합니다. 중요한 것은 앞에 있는 weigh입니다. sigmoid function 값이므로 weight은 0~1 사이의 값을 갖는 양수인데요, reward model이 \( y_w \) 의 reward를 \( y_l \) 의 reward 값보다 낮게 측정하는 오류를 범했다면 weight 값이 1에 가깝게 커지는 구조입니다.
저자들은 이 weight을 1로 둔 naive version으로 실험해봤는데 (그렇게 구성해도 말이 되는 loss임), degeneration 문제가 심각하게 발생했다고 하네요. 이 gradient에서 이러한 weighting의 중요성을 강조하고 있답니다.
Experiments & Results
이 논문에서는 세 가지 데이터셋으로 실험한 결과를 보여줌으로써 성능을 입증하고 있습니다. 평가는 GPT-4에 prompt를 잘 작성하여 수행한 것으로 나와있습니다.
- IMDb Sentiment Generation: 긍정적인 영화 리뷰를 생성할 수록 높은 reward를 받을 수 있는 task
- TL;DR: Reddit에 올라온 게시물 텍스트 요약 과제
- Antrhopic-HH Dialogue: human-assistant간 1-turn의 대화를 수행하는 task

Figure2 (좌측) 기존 policy와 크게 분포가 다르지 않도록 제약한 환경에서는 DPO가 압도적으로 reward를 극대화 합니다. 효율적인 알고리즘으로 해석할 수 있습니다. hyperparameter를 조정한 학습을 통해 기존 policy와의 분포에서 멀어지도록 자유도를 더 주어도 DPO가 잘하는 모습을 볼 수 있습니다.
(우측) 사람이 작성한 요약과 품질을 비교하는 태스크입니다. temperature에 따른 sampling option을 다르게 주어도 PPO보다는 성능이 좋은 것을 볼 수 있고, Best of 128, 즉 해당 temperature에서 128개를 샘플링 한 요약 중 가장 좋은 요약과 비교해도 DPO가 거의 더 높습니다.

Figure 3 (좌측) Antrhopic-HH Dialogue Set에서도 비슷한 좋은 성능을 보여줍니다.
(우측) Fine-tuning step의 가장 초기에서도 벌써 win rate이 거의 수렴한 것으로 보아 DPO 학습이 꽤나 효율적임을 알 수 있습니다. 2400 step 이후에는 win rate이 약간 감소하는 것처럼 보이는데, 저자들은 이에 대한 후속 연구가 필요하다는 점을 언급하고 있습니다.

degeneration 현상의 예시 기존 알고리즘들도 reward over-optimization으로 인한 degeneration 현상을 보였는데 DPO 알고리즘도 같은 문제를 가지고 있는 것이 아닌지 말이죠. DPO가 연구의 첫 발을 내디딘 만큼, policy가 reward model을 완전히 대체하려는 시도가 정말 괜찮은 시도인지에 대한 검증이 꾸준히 이루어져야 할 것 같습니다.
Avaliable Code
벌써 huggingface의 DPO Trainer가 나왔습니다! 사용 방법도 간단하니 PPO를 고려하셨던 분들은 DPO Trainer도 사용해보시는 건 어떨까요? 기존 방법론들 대비 간단하다는 점이 매우 마음에 듭니다.
DPO Trainer
huggingface.co
'Paper Reviews' 카테고리의 다른 글
[논문 리뷰] KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents (0) 2024.04.15 초거대 LLM 24배 빠르게 서빙하기 (0) 2023.11.02 상용화된 LLM에서 얻은 피드백 활용 방법 (0) 2023.10.31 LLAMA2를 무해한 모델로 만들기 위한 노력 (0) 2023.08.24 LEVER: Learning to Verify Language-to-Code Generation with Execution 논문 리뷰 (0) 2023.08.16
